Linux 命名空间原理 & pod 调试
一、前言
原理
Namespace 是 linux 的一种资源隔离方案,最早是用于解决一台机器多用户登录操作多进程的隔离问题,后来延用于 Hypervisor,Docker 等虚拟化技术中。

Linux的每个进程都具有命名空间,可以在/proc/$PID/ns目录中看到命名空间的文件描述符
命名空间的种类
Linux 目前提供了 6 种命名空间,每种命名空间有自己的资源隔离类别。
1.Mount namespaces:提供磁盘挂载点和文件系统的隔离能力
2.UTS namespaces :提供主机名隔离能力
3.IPC namespaces :提供进程间通信的隔离能力
4.PID namespaces :提供进程隔离能力
5.Network namespaces :提供网络隔离能力
6.User namespaces:提供用户隔离能力
三、Pod 命名空间
Pod 是 k8s 的最小单位,一个 pod 下可以运行多个容器,他们共享网络和存储。
Pod 在启动的时候会先创建 pause 容器,作为其它容器的父容器,提供了网络和存储相关的命名空间并共享给其它业务容器(IPC NS、Net NS、PID NS)
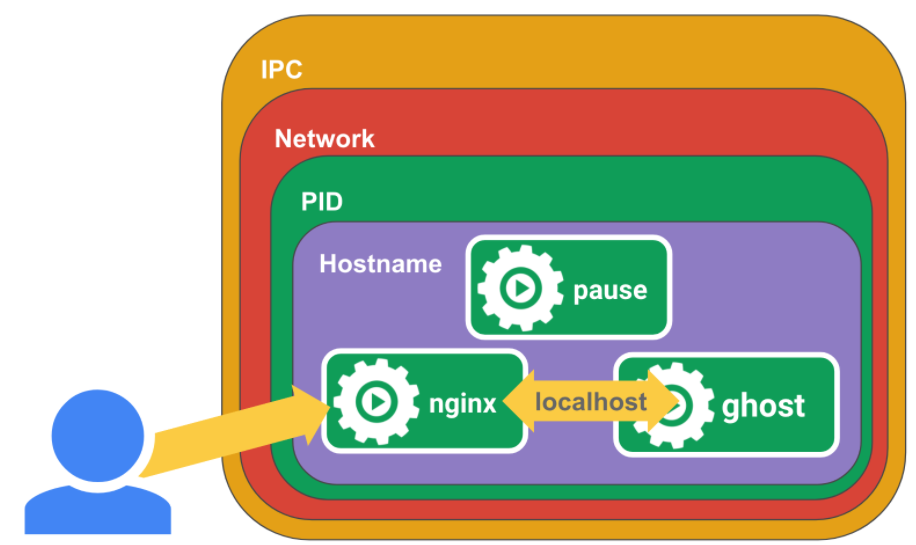
kubernetes中的pause容器主要为每个业务容器提供以下功能:
- 在pod中担任 Linux 命名空间共享的基础;
- 启用 pid 命名空间,开启 init 进程。
登录节点查看对应负载的容器,都可以看到多了一个 pause
[root@test1-cluster-79890 ~]# docker ps |grep hotwheel-admin
bc85fc0438db swr.cn-north-4.myhuaweicloud.com/yummy-default/hotwheel-admin-develop-1 "/sbin/tini -- /bin/…" 2 hours ago Up 2 hours k8s_hotwheel-admin_hotwheel-admin-5557f9fcdc-ktj5c_default_c6f074cb-f30a-44b4-a8ff-b74c9de13cce_0
859e8499384d cce-pause:3.1 "/pause" 2 hours ago Up 2 hours k8s_POD_hotwheel-admin-5557f9fcdc-ktj5c_default_c6f074cb-f30a-44b4-a8ff-b74c9de13cce_0四、nsenter 工具使用
我们可以利用命名空间的原理,进入容器相关命名空间,即可查看和调试对应的容器。nsenter 就是 linux 访问命名空间的一个工具。并且在容器的命名空间里面,我们可以直接使用宿主机的工具。这样我们可以不用对基础容器安装各自调试用的工具。
基础语法
nsenter [options] [...]
[root@test1-cluster-79890 ~]# nsenter --help
Usage:
nsenter [options] [...]
Run a program with namespaces of other processes.
Options:
-t, --target target process to get namespaces from
-m, --mount[=] enter mount namespace
-u, --uts[=] enter UTS namespace (hostname etc)
-i, --ipc[=] enter System V IPC namespace
-n, --net[=] enter network namespace
-p, --pid[=] enter pid namespace
-U, --user[=] enter user namespace
-S, --setuid set uid in entered namespace
-G, --setgid set gid in entered namespace
--preserve-credentials do not touch uids or gids
-r, --root[=] set the root directory
-w, --wd[=] set the working directory
-F, --no-fork do not fork before exec'ing
-Z, --follow-context set SELinux context according to --target PID
-h, --help display this help and exit
-V, --version output version information and exit
For more details see nsenter(1).
PID 查找
从负载找到对应的容器进程 ID ,使用起来稍微麻烦了点。
- 确认负载所在节点
- 登录指定节点并根据容器名称过滤
docker ps |grep hotwheel-admin
- 根据容器 ID,查找容器 pid
[root@test1-cluster-79890 ~]# docker inspect -f {{.State.Pid}} bc85fc0438db
5888 进入容器的命名空间
# 进入 12688 进程的网络命名空间
nsenter -t 12688 --net
# 在网络命名空间查看的 ip 情况 【只有 2个网卡】
[root@test1-cluster-34867 ~]# ifconfig
eth0: flags=4163 mtu 1500
inet 172.19.3.70 netmask 255.255.0.0 broadcast 0.0.0.0
ether fa:16:3e:3b:0c:4d txqueuelen 0 (Ethernet)
RX packets 65333 bytes 73376361 (69.9 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 60041 bytes 11472220 (10.9 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73 mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
loop txqueuelen 1000 (Local Loopback)
RX packets 4 bytes 200 (200.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 4 bytes 200 (200.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# 退出命名空间后,再查看网络,发现是宿主机的网络信息了,比较多就没展示
[root@test1-cluster-34867 ~]# exit
logout
# 进入进程的多个命名空间
nsenter -t 12688 --uts --ipc --net --pid
并不是所有资源都有被 ns 隔离
- Linux中并不是所有的资源都可以使用 namespace 来隔离,比如SELinux、time、syslog。
- namespace的隔离也是不全面的,比如/proc 、/sys 、/dev/sd*没有完全隔离。
在容器里面执行 top
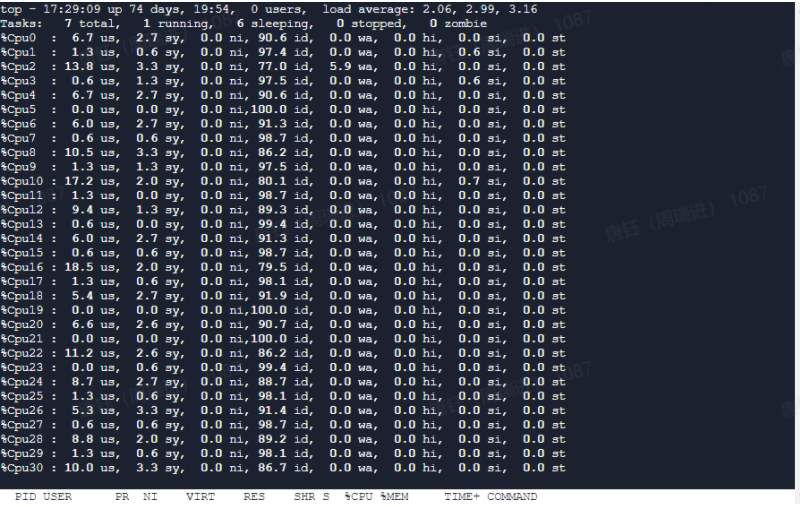
在容器里面执行 free -h

上面的命令可以看出,容器里面展示的 cpu 跟 内存 都是宿主机的。
free主要读取/proc或/sys目录
Docker的设计者也意识到这样确实存在很大不便,于是从Docker在1.8版本以后将分配给容器的cgroup资源挂载到容器内,可以直接在容器内部查看到cgroup资源隔离情况。
# 查看容器核数,除100000
cat /sys/fs/cgroup/cpu/cpu.cfs_quota_us
# 获取内存使用
cat /sys/fs/cgroup/memory/memory.usage_in_bytes
cat /sys/fs/cgroup/memory/memory.limit_in_bytes
# 注意这里已经使用的内存usage_in_bytes是包含cache的,详细的情况可以从/sys/fs/cgroup/memory/memory.stat中获取
# 查看容器是否设置oom,oom_kill_disable默认为0表示开启
cat /sys/fs/cgroup/memory/memory.oom_control
# 获取磁盘io
cat /sys/fs/cgroup/blkio/blkio.throttle.io_service_bytes
# 获取网卡出入流量
cat /sys/class/net/eth0/statistics/rx_bytes
cat /sys/class/net/eth0/statistics/tx_bytes
异常容器的调试
异常的容器可以分两类:
- 容器有启动成功:可能是健康检测不过(容器仍然支持进入)
- 容器没有启动成功:可能镜像拉不下来,cmd 命令错误等(容器没有创建,无法进入)

上图的容器
CrashLoopBackOff 异常
# 通过 docker ps 只看到了 pause 基础容器,没有业务容器
[root@test1-cluster-34867 ~]# docker ps |grep hello
0fdd608f1424 cce-pause:3.1 "/pause" 7 minutes ago Up 7 minutes k8s_POD_hello-spring-547bcb7b75-52p47_default_c68c481c-4e36-47f2-963c-47b885a7ea98_0
我们知道 pause 跟业务容器是在同一个 pod 中,共享网络和存储,如果只是调试网络问题,进到 pause 的命名空间也是一样的。
[root@test1-cluster-34867 ~]# nsenter -t 56635 --net
[root@test1-cluster-34867 ~]# ifconfig
eth0: flags=4163 mtu 1500
inet 172.19.3.122 netmask 255.255.0.0 broadcast 0.0.0.0
ether fa:16:3e:3b:0c:4d txqueuelen 0 (Ethernet)
RX packets 384 bytes 16954 (16.5 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73 mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
loop txqueuelen 1000 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0

上图可以看出, pause 命名空间执行 ifconfig 查询到的 ip 跟容器 ip 一样。
五、k8s-debug
k8s-debug 工具也是利用了 ns 的原理,但是对 k8s 的版本有一定限制。
五、行业发展方向
通过 ns 原理,我们在宿主机可以访问所有容器的信息,甚至不需要 ssh,exec 等命令。基于云厂商的 k8s 服务未来的趋势肯定是要解决这个隐患。更轻量,更安全是整个行业的趋势。
无法复制加载中的内容
- 基于虚拟化的机密计算:TDX 、SEV 、PEF
- 镜像功能卸载:主机上看不到容器镜像
- 远程认证:确保运行在机密环境中
发表评论 取消回复